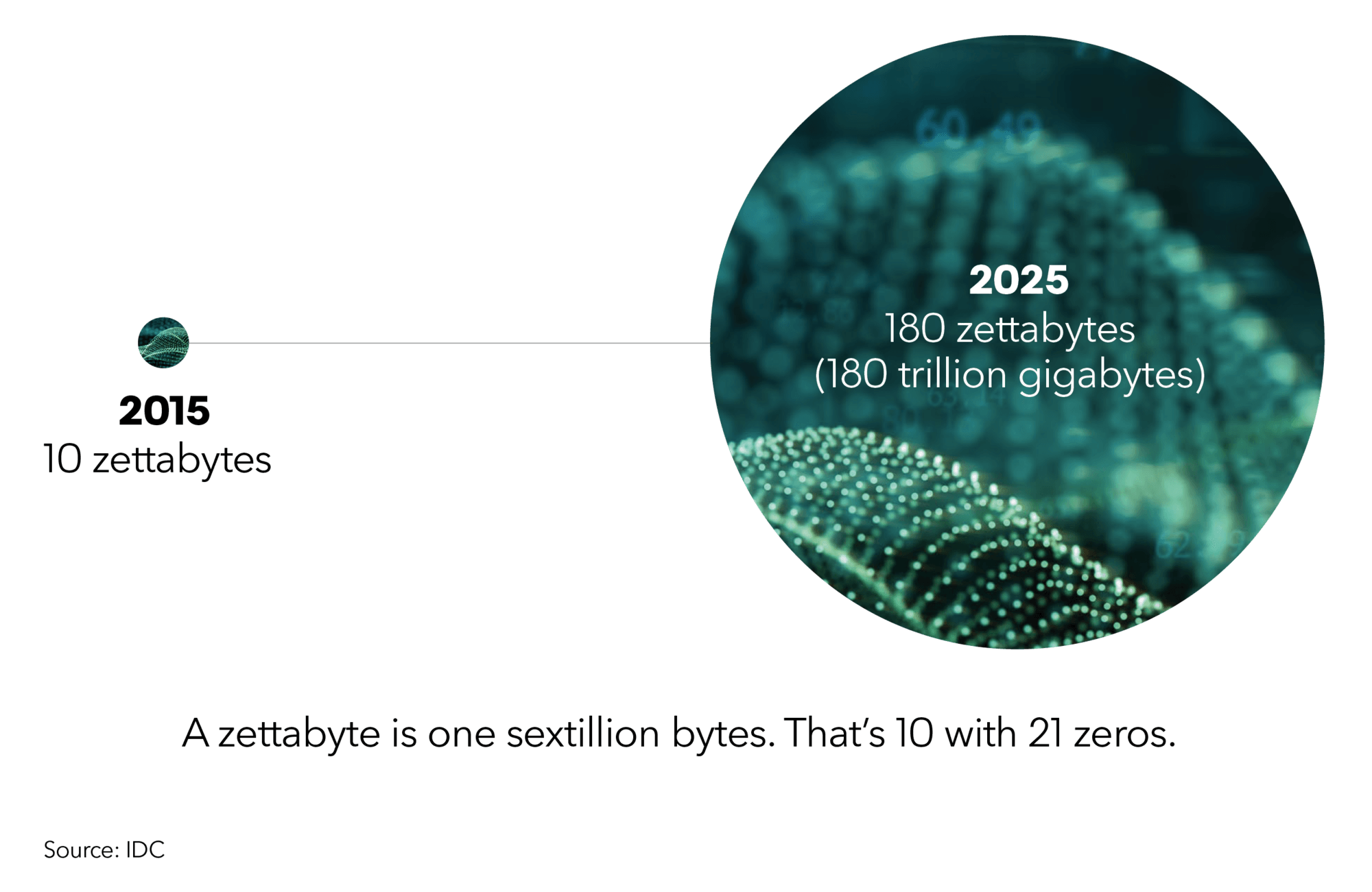全球数据正以不可思议的速度爆炸性增长,但企业拥有大量数据储备却并未对其开发利用。
全球数据的增长速度令人难以置信:每隔两年数字世界的规模至少会扩大一倍。
数据资讯快速增长的结果是,许多企业坐拥的大量未经开发的数据储备,这些数据都是零散的,格式也不兼容。
有数据资本化策略的企业纷纷通过投资的方式来尽可能地从大数据中挖掘价值。任何可靠的数据策略都有一个关键部分,就是稳健的数据质量流程。
对企业而言,考虑短期解决方案和人工的数据清洗流程固然是具有吸引力的做法,但对于任何长期的,可重复性的数据相关策略来说,采用算法工具更为合适。
这是挑战,也是机遇
尤其对金融服务企业来说,大数据既是挑战,也是机遇。眼下,企业手中的数据比以往任何时候都多,但要了解并有效利用这些数据却并非易事。
彭博的数据许可部门负责人Matthew Rawlings指出,问题主要源于一些实际情况,“事实上,要清洗并运行这些数据需耗费大量人工,并辅以一些商业智能”。
许多公司在做出数据驱动的决策时都存在时间上的滞后性——当数据被定位,清洗,归类然后应用时,事实上已经过时了,相关性荡然无存。如果数据质量达不到标准,企业还会遇到严重的问题,既有监管层面的,也有商业层面的。
的确,在对2017年北美金融信息论坛参会代表所作的会前调查中,仅刚过半(51%)的受访者把数据质量视为迫在眉睫的最大障碍。
一年的流程,缩至一天
可能是由于这些驱动因素,越来越多的先锋者正转向机器学习领域,利用复杂的人工智能技术,在数据质量方面影响技术革命。人工智能的能力在指数级应用和影响力上正处于临界点。
举例而言,设想某家大银行日常和NatWest银行 (National Westminster Bank)有业务往来。在不同的企业部门、数据库和Excel表格中,客户名字可能会出现多种不同的写法,如County NatWest、NatWest、Nat West或National Westminster等等。整合这些不同的输入要耗费大量人力。
但是使用计算机程序,理论上可以扫描并处理银行内不同平台的数据,并在几个小时内完成比对。“这家大银行可以立刻看出整个公司在NatWest银行上的敞口,” Rawlings解释道,“这使他们可以更快、更好的做出决策”。
此流程,也就是命名识别,只是机器学习能够带来变革的诸多领域之一。而且随着时间的推移,流程还会改进。
以 NatWest为例,最初的扫描结果可能显示在第一次试验中报错率为10%或15%,但随着持续不断的反馈,机器可以从错误中吸取教训,在下一批数据中应用调整后的法则。这种持续的改良正是机器学习技术如此高效的原因,它清理和验证数据的速度是过去认为不可能实现的。
机器学习确保数据质量
运用此类技术可以确保整个企业平台的数据质量,彭博PolarLake的首席执行官 John Randles先生在一场网络研讨会上对一家全球资产管理公司也提到了这个案例。
“我们发现用来形容数据的元数据和实际数据源本身存在上百万个错配,而我们花了超过15个月的时间才清除掉这些问题,”如果采用数据集,问题的数量可以从几百万个减少到几千个。
使用正确的技术可以满足企业的一项核心需求,即在情境中采取数据。 Northern Trust Corporation的企业数据管理部门负责人Sanjay Saxena表示,上下文情境是评估数据质量的最重要方面,他在一次网络研讨会上指出,“当您可以解释日常工作情境中的数据时,灵感就来了。”
数据管理的最佳应用方式得到了显著改善,因为计算机运算能力有关的成本大幅下降,数据可获得量增加,而且开源机器学习工具被更多的放开,使得许多企业具有了应用人工智能技术的能力。
新的数据科学方法和最佳应用方式令数以亿计的数据变成了有意义的资讯。对有数据调研能力的机构而言,数据质量依然是分水岭。
总而言之,人类无法达到解读ZB级数据的分析速度,这就是为什么机器学习的基础如此重要。