Por Bruno Dupire
Establecer un vínculo entre los observables actuales (los datos estructurados y no estructurados) y el comportamiento futuro es una gran tarea en finanzas, y naturalmente el campo está adoptando el aprendizaje automático para abordar esta típica tarea de aprendizaje. Esto requiere ampliar el rango de datos y métodos, y sacudir algunos viejos hábitos.
Convencionalmente, la mayoría de los datos financieros fueron procesados de manera estructurada, como la información numérica de los mercados y los precios de los valores, y los métodos para procesarlos se tomaron prestados del conjunto de herramientas estadísticas estándar. Los avances en el aprendizaje automático y en el poder de procesamiento significan que ahora es posible procesar (y encontrarle sentido a) grandes cantidades de datos no estructurados, lo que trae consigo el potencial de transformar la industria.
La relevancia en el conjunto de datos
Los participantes del mercado están reconociendo gradualmente que muchas dimensiones del mundo están interconectadas, y que discernir esta red de interacciones puede desatar algún poder de pronóstico. Ahora, las fuentes previamente ignoradas se están extrayendo para obtener datos importantes y potencialmente rentables.
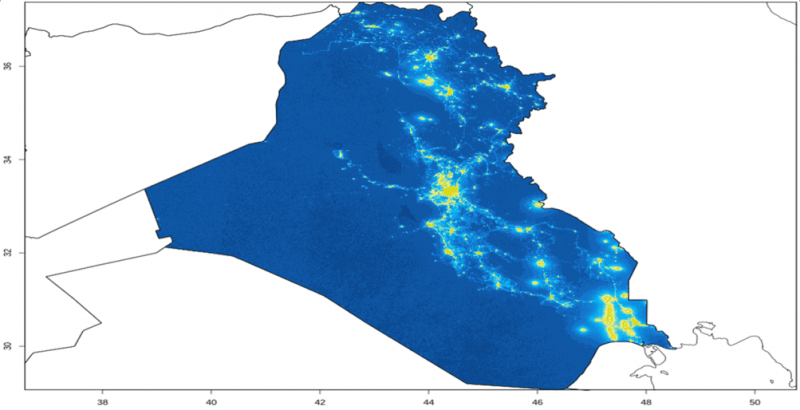
Las imágenes satelitales de intensidad de luz nocturna, las sombras de los tanques de aceite y la cantidad de autos en estacionamientos, por ejemplo, pueden utilizarse para estimar una actividad económica. La actividad en redes sociales y las noticias pueden utilizarse para determinar un sentimiento, mientras que el uso de la tarjeta de crédito puede revelar tendencias importantes del gasto de los consumidores.
Un primer conjunto de técnicas transforma los datos brutos en un valor numérico: una imagen satelital nocturna se convierte en una medida de intensidad de la luz; se analiza una foto de un estacionamiento para revelar la cantidad de automóviles; el lenguaje de un artículo de noticias o tweet se coloca en un índice de polaridad para predecir una percepción positiva, negativa o neutral.
Un primer conjunto de técnicas transforma los datos sin procesar en un valor numérico. Por ejemplo:
Imagen 1: Imagen satelital nocturna - medida de la intensidad de la luz Imagen 2: Artículo de noticias o tweet - índice de polaridad (bueno/malo)
El siguiente paso es utilizar esta información para realizar pronósticos. ¿Podemos usar la intensidad de la luz para pronosticar el gasto versus el PIB de un país? ¿Podemos estimar las ganancias al observar los estacionamientos de Walmart, etc.? ¿Podemos estimar el retorno del precio o la volatilidad de una empresa al utilizar la percepción de las redes sociales sobre esa compañía?
Métodos de aprendizaje automático
Existen varios tipos de métodos de aprendizaje automático que se pueden utilizar según el tipo de datos disponibles y el objetivo. Los más comunes son:
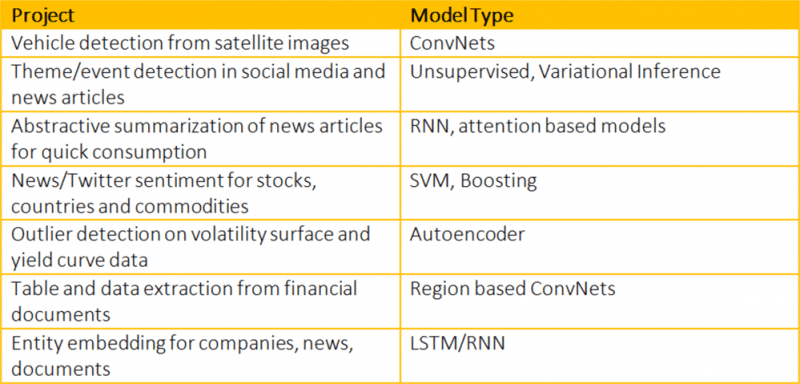
La lista de tareas que se pueden beneficiar del aprendizaje automático es interminable. La siguiente tabla muestra algunos de los proyectos de aprendizaje automático en los que estamos trabajando en Bloomberg:
Autoenconders para una reducción de la dimensionalidad
Un uso interesante de las redes neuronales es para reducir la dimensionalidad de, por ejemplo, las curvas de rendimiento o las superficies de volatilidad. Para las curvas de rendimiento, tradicionalmente la técnica más popular utilizada es el análisis de componentes principales (PCA). En el contexto de la curva de rendimiento, los tres componentes más importantes se identifican como desplazamiento paralelo, pendiente y giro.
Una red autoencoder es más eficiente para la reducción de la dimensionalidad que el PCA, ya que puede hacer un uso completo de la no linealidad que genera. Una red autoencoder pretende reproducir como resultado el dato inicial forzado a través de un cuello de botella que destila información de entrada en una representación compacta. Por lo general, se observa que funciona mejor que el PCA cuando hay un cambio en el comportamiento global o un cambio en el régimen.
Podemos utilizar algoritmos de aprendizaje supervisado para conocer señales que puedan generar alfa o aprender a construir carteras para diferentes condiciones de mercado. Dos ejemplos de este tipo son:
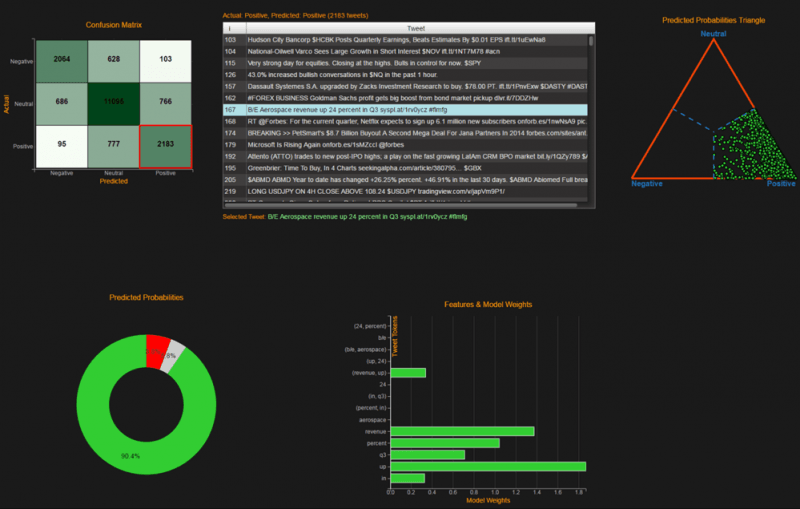
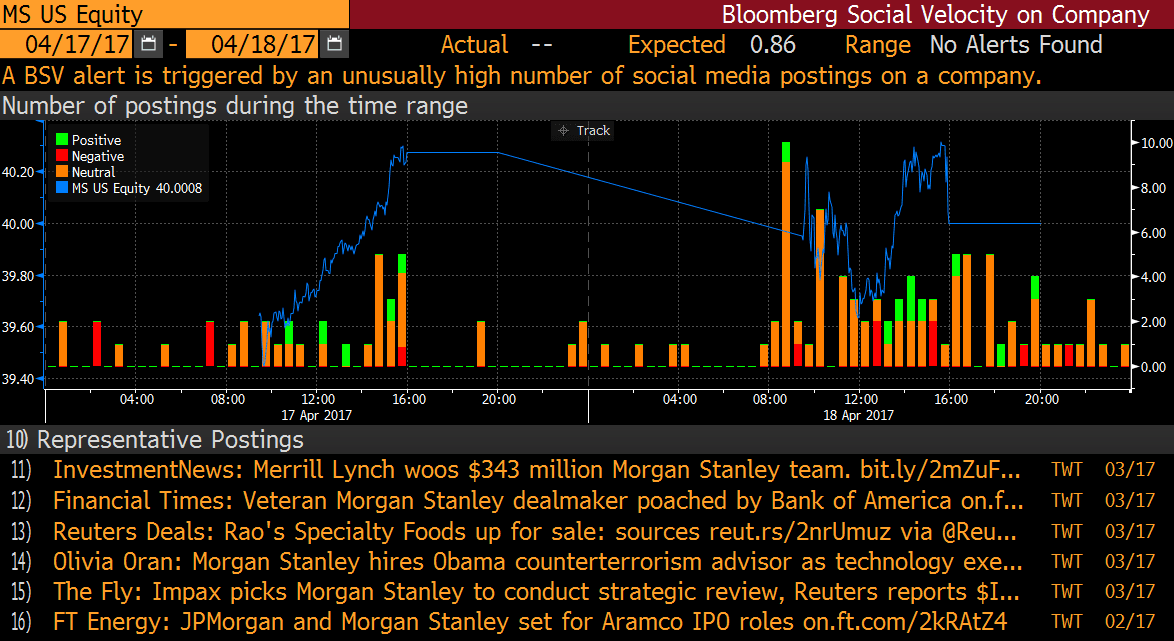
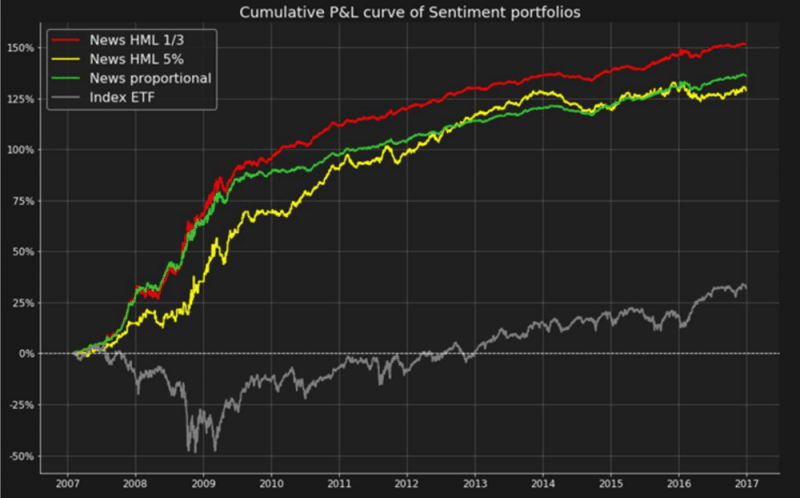
1. Estrategias basadas en la perspectiva: el texto de los tweets o noticias puede analizarse y etiquetarse automáticamente como expresión de perspectivas positivas, neutrales o negativas. Por ejemplo, el siguiente cuadro resume el número de las tres clases de tweets para una acción (MS) por cada intervalo de 15 minutos durante un período de dos días.
El análisis de estos datos procesados da lugar a señales de trading que pueden utilizarse para construir una estrategia de negociación, por lo general alargando las acciones de percepción positiva y acortando las negativas. En el siguiente cuadro podemos ver que dicha cartera supera significativamente al mercado.
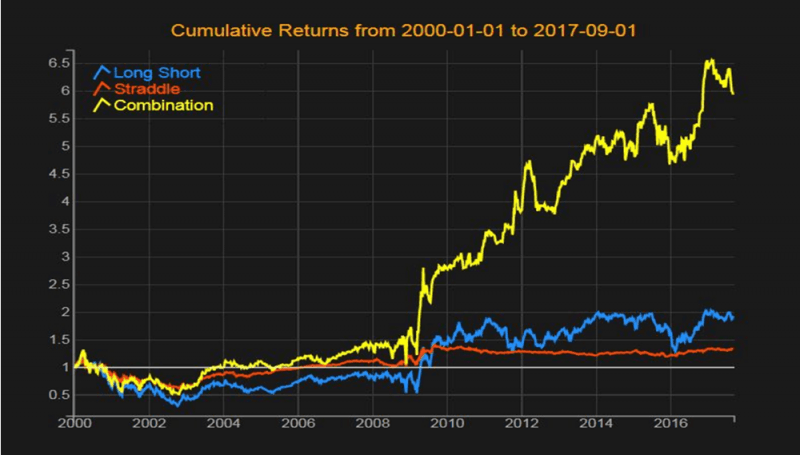
2. Estrategias beta inteligentes: Otra forma de utilizar los datos para elaborar una estrategia operativa es encontrar un conjunto de características que representen las condiciones del mercado y luego definir una lista de factores o estrategias. Luego, la tarea de aprendizaje es establecer un enlace entre las condiciones del mercado en un momento específico y la mejor estrategia para aplicar en el subsiguiente período.
Ejemplos de características que pueden ser utilizadas para definir las condiciones del mercado son: retornos de SPX; nivel VIX; pendiente de la curva de rendimiento; márgenes de crédito; y la inflación. Ejemplos de estrategias son: carteras con valores ponderados de acuerdo con el valor/rango de un parámetro como la versión beta de las carteras; y diferentes fondos smart beta, como los asociados con los factores French Fama o regiones o sectores industriales.
El aprendizaje supervisado consiste en conocer durante el período de capacitación la asociación entre las estrategias más rentables y las condiciones de mercado correspondientes. Una vez que el sistema haya aprendido estas asociaciones y pueda imitarlas, se prueba en un período fuera de la muestra.
Este gráfico ilustra el beneficio de aprender a moldear dinámicamente una cartera de acuerdo con los centiles beta y cómo supera a una cartera típica a corto y largo plazo.
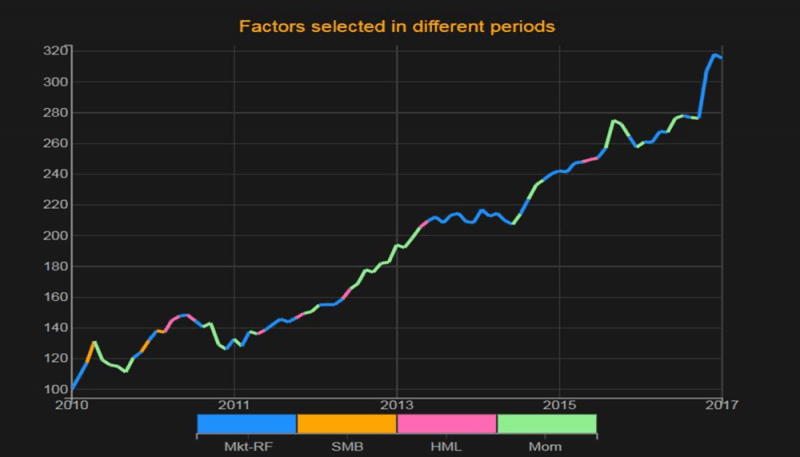
Este gráfico muestra la estrategia óptima seleccionada para la construcción de una estrategia de rotación de las carteras del factor Fama-French:
Conclusión:
La disponibilidad de nuevos conjuntos de datos y técnicas, y el aumento en el poder de la informática han ampliado las aplicaciones del aprendizaje automático en las finanzas. El campo aún es incipiente y está lleno de trampas, pero es una gran promesa ya que una nueva generación de técnicas, herramientas y talento comienza a desarrollar todo su potencial.